
The cost function for Linear Regression is Mean Squared Errors. It goes like below:
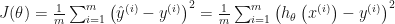



To find the best weights that minimize the error, we use Gradient Descent to update the weights. If you have been following Machine Learning courses, e.g. Machine Learning Course on Coursera by Andrew Ng, you should have learned that to update the weights, you need to repeat the process below until it converges:
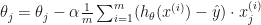
In Andrew Ng’s course, it it also expanded to:
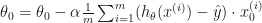
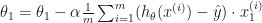
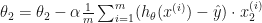
…
Let’s make this less abstract by putting down exact data point with a small sample and feature sizes. Let’s say, we have a set of data with 4 features like below and we only select 3 samples from it for simplicity.
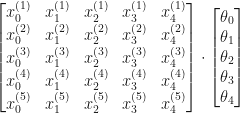
The prediction for each sample is:
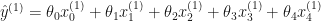
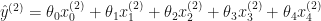

In this case the cost function wold be:
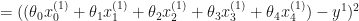
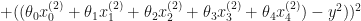
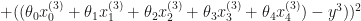
To minimize the cost, we need to find the partial derivatives of each 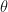

Let’s find the derivative of the 


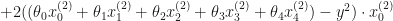
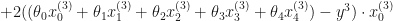
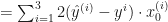
Do the same for the rest of the


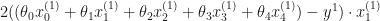
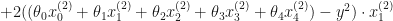
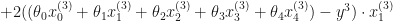
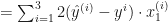

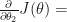

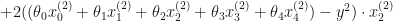
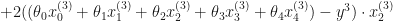
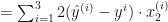
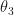


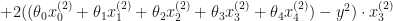

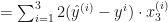


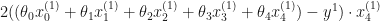
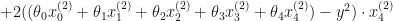
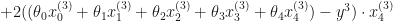
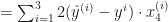
If you are at first unclear about the functions and notations in the courses or some other documentations, I hope the expansion above would help you figure it out.
